Building a Named Entity Recognition model
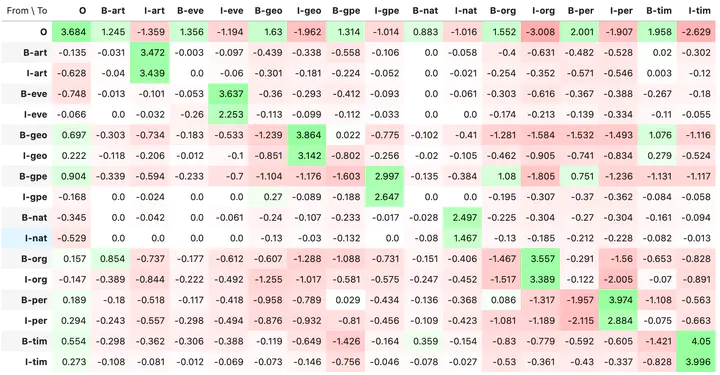 Transitional weights between different Named Entities (as provided through eli5 library)
Transitional weights between different Named Entities (as provided through eli5 library)
Named Entity (NE) Recognition classifier in pytorch and sklearn
Given a set of documents, can we identify what the most important entities mentioned are?
Can we classify terms as relating to dates, times, organisations and geopolitical entities so that we can take any text (such as a news article) and automatically extract information and use it to populate summary tables or to help search queries?
Moreover, how successfully can we train a model to identify the entirety of an NE token and not over-tagging or under-tagging words around the NE?
This project is split into two parts, each using a different methodology to achieve the stated goal above: Part 1: Using traditional Machine Learning models and techniques to predict NEs. Part 2: (Work-in-progress) Using neural network architectures for the same purpose.
Part 1:
In this project so far I have built a baseline feature-based model to serve as a comparison and for interpreting feature importance and detecting underlying statistical trends in our data. It has achieved a macro-average F1 score of just under 0.7, so there is room for improvement.
Note that F1 score takes into account 2 features: precision and recall, which can be interpreted as below:
- Precision : out of all the NEs we identified, what proportion were correct? (this doesn’t take into account the NEs not identified at all)
- Recall : out all the words that are actually NEs, what proportion did we correctly identify?
We report on this rather than accuracy (which was at 95%), because we have an extremely unbalanced dataset.
Examples
Let’s go through some examples of the model’s outputs on the validation data. Below is a sentence that where the model achieved a perfect score, identifying the beginning (B-) and inside (I-) components of an NE. 'tim' refers to a time indicator (which can vary from ’noon’ to ‘41st millenium’). All the ‘O’ rows are of course, non-NEs. This is a somewhat easy task however, as the model was presented with a short sentence and a single, 2-part NE.
| True | Pred | Word |
|---|---|---|
| O | O | its |
| O | O | golden |
| O | O | age |
| O | O | occurred |
| O | O | in |
| O | O | the |
| B-tim | B-tim | 16th |
| I-tim | I-tim | century |
| O | O | . |
In the next example we see that the the model overestimated the boundaries of one NE at the expense of another, labelling ‘U.S. Vice’ as an organisation (org), when ‘Vice President Dick Cheney’ should have been entirely labelled a person (per). It will be interesting to see how the attention-based model navigates these fine boundaries between NEs. The model understandands the data broadly on two categories of features we’ve trained it on:
| True | Pred | Word |
|---|---|---|
| O | O | the |
| O | O | event |
| O | O | will |
| O | O | be |
| O | O | attended |
| O | O | by |
| O | O | many |
| O | O | foreign |
| O | O | dignitaries |
| O | O | , |
| O | O | including |
| B-org | B-org | u .s. |
| B-per | I-org | vice |
| I-per | B-per | president |
| I-per | I-per | dick |
| I-per | I-per cheney | |
| O | O | . |
-
The in-word (or in-sentence features), such as whether it’s a nouns/adjective/verb/etc.., what its last 3 letters are, what POS (part-of-sentence) the word before was, and so on.
-
The transitional weights between different NEs, i.e. if the model’s just seen the start of a organisational entity, how likely is it a that the next chunk will the inside of an organisational entity (we know that the model gives this transition a weight of 3.757, which is comparatively high).
So, when the model considered ‘vice’ to be the inside chunk of an organisational entity, it takes that into account first, then uses the other features about the word ‘Vice’ to decide that it’s more likely to be be an I-org than a B-per. The model also then has to compare this to the calculated probability that ‘Vice’ is a ‘B-per’ and goes with whichever is higher.
This final example is a partial misclassification of the named entity of the “Interim Prime Minister Ali Mohamed Gedi”. Notice that the model managed to determine almost all of the NE correctly, except for “interim”, mistaking that for an artefact.
| True | Pred | Word |
|---|---|---|
| O | O | last |
| B-tim | B-tim | thursday |
| O | O | , |
| O | O | the |
| O | O | convoy |
| O | O | of |
| B-per | B-art | interim |
| I-per | B-per | prime |
| I-per | I-per | minister |
| I-per | I-per | ali |
| I-per | I-per | mohamed |
| I-per | I-per | gedi |
| O | O | was |
| O | O | also |
| O | O | attacked |
| O | O | while |
| O | O | traveling |
| O | O | in |
| B-geo | B-geo | mogadishu |
| O | O | . |
This would have naturally been counted as a misclassification, but, all things considered, if you were reading a text highlighted automatically and it was only “interim” absent from the highlighted B-per text, you’d probably gloss over that mistake.
Part 2 (WIP):
The most successful developments in this area have employed neural network architectures[2], which is what I ultimately be building for this project.
By the end I hope to have achieved a reasonable neural classifier (with an macro-averaged F1 score above 0.8) that utilises an attention layer to capture inter-word dependencies.
As an additional goal, I would like to deploy this model to via AWS to a web app that can interactively highlight NEs within the text.
Additional Background Notes
A named entity (NE) is a word or group of words “that clearly identifies one item from a set of other items that have similar attributes”[1]. Identifying and labelling important NEs in text data is a key challenge in Natural Language Processing (NLP). NER has many useful applications in the wider NLP space, such as creating new data features for Information Extraction systems, improving performance in Machine Translation and Summarisation systems or simply providing a way to highlight relevant entities within a text for a reader’s convenience[1]. Solutions to the problem can be categorised in four groups: rule-based algorithms, unsupervised learning approaches, feature-based supervised learners and deep learning techniques. This project will focus on the last two.
(LINK to youtube video; and/or blog post)
The target labels for sequence classification come in two parts, the BIO tag which refers to:
- B - beginning of NE chunk
- I - inside NE chunk
- O - not an NE
and the label stating what type of
- geo = Geographical Entity
- org = Organization
- per = Person
- gpe = Geopolitical Entity
- tim = Time indicator
- art = Artifact
- eve = Event
- nat = Natural Phenomenon
Significant findings/ Executive Summary (so far …)
Using sklearn’s Conditional Random Field suite and the seqeval package for evaluation, my Minimum Viable Product has achieved a macro-average F1 score of 0.696. The table below shows this model’s performance on the different categories (‘support’ refers to number of instances of each type within the validation data set).
| Entity type | precision | recall | f1-score | support |
|---|---|---|---|---|
| geo | 0.69 | 0.73 | 0.71 | 422 |
| gpe | 0.77 | 0.79 | 0.78 | 218 |
| per | 0.75 | 0.69 | 0.72 | 206 |
| tim | 0.86 | 0.73 | 0.79 | 243 |
| art | 0.00 | 0.00 | 0.00 | 5 |
| org | 0.52 | 0.48 | 0.50 | 226 |
| eve | 0.50 | 0.27 | 0.35 | 15 |
| nat | 0.00 | 0.00 | 0.00 | 1 |
| ———— | ————- | ——– | ———– | ——- |
| avg / total | 0.71 | 0.68 | 0.69 | 1336 |
MVP Model interpretation:
Using eli5 package we can investigate what the weights between different states (i.e. the Named Entities) are, as well as effect of different features on the likelihood of predicting a feature as being of any particular state (see Fig 1 below):
Transition weights between Named Entity States:
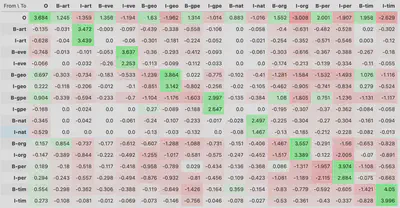
Samples of some weights for different features for just two entity classes:
OSEMN
OBTAIN
- download dataset
SCRUB
- dataset is very clean, as has been confirmed by multiple previous users on Kaggle
EXPLORE
- visualise target category distributions; use spacy’s EDA methods to show NER in action, as shown in notebook 2;
MODEL
- after performing a train-validation-test split, I transform the data to be adequate for a feature-based CRF model. This will involve turning text data into an array of numbers encoding certain features (e.g. {text.isupper(), text.istitle(), len(text), … }, interactions of those features and the provided POS tag for the word. Use GridSearchCV to cross-validate and optimise.
- Use a pytorch RNN-based model to perform NER. I will build the preprocessing and vectorisation steps required for adequately preparing the data for this task. The first neural network layer will be the Lookup layer that matches the token to the pre-trained GloVe Vectors [3]. Using pre-trained language model vectors like GloVe has been shown consistently to improve model performance across a variety of NLP tasks. Time-permitting I will add an Attention Layer to the neural model. The training for this model will occur in AWS Sagemaker.
- To help with correctly measuring performance, I’ll be using the seqeval library for my measures of F1 and precision.
INTERPRET -
- CRF model will be easier to interpret and I’ll be able to extract interesting dependencies between created features and the target values. The aforementioned Kaggle post shows one method of doing this. Knowing such dependencies will also be useful in gauging how successful the model will be on future, unseen data.
- To interpret the neural model, I will pass in more recent news articles into it to check which entities in particular are (mis)classified as which categories. If it were possible, it would be great to find and use a python-friendly text highlighter that would encode predictions directly in the text.
Filing system:
Notebooks 2. Baseline_model_CRF.ipynb - Conditional Random Fields model is fitted, tested and optimized here with gridsearch 3. EDA.ipynb - exploration of the data and the distribution of words, POS, and TAGs, as well as some consideration of how to create a feature-based model 4. data_cleaning.ipynb - notebook detailing the entire cleaning process (very minimal, given the data)
Folders
- clean_data - folder containing clean data and any additional summary data generated; feature-based data and vectorised representations will be stored here
- raw_data - data as it was when imported / downloaded / scraped into my repository
- archive - any additional files and subfolders will be here
- glove - folder containing Global Word Vector Representations (as produced by the Stanford NLP group)[2]
- crf_model - pickle files of the optimized CRF model
References: 1. Charles Sutton and Andrew McCallum (2012), “An Introduction to Conditional Random Fields”, Foundations and Trends® in Machine Learning: Vol. 4: No. 4, pp 267-373.http://dx.doi.org/10.1561/2200000013 2. @misc{li2018survey, title={A Survey on Deep Learning for Named Entity Recognition}, author={Jing Li and Aixin Sun and Jianglei Han and Chenliang Li}, year={2018}, eprint={1812.09449}, archivePrefix={arXiv}, primaryClass={cs.CL}} 3. Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation.