Sentiment Analysis with Pytorch
 AWS Icon from uxwing.com
AWS Icon from uxwing.com
Sentiment Analysis in Pytorch
Training and deploying a Sentiment Analysis model in Pytorch using AWS Sagemaker. The data used was IMDB’s Movie review dataset (https://ai.stanford.edu/~amaas/data/sentiment/), which consists of 50,000 instances of binary labelled movie reviews.
How do we take a machine learning model and put it out there to be used?
How do we deploy an inference model out there in the real world, to interact with a user?
Amazon Web Services platform allows us to train, host and deploy a variety of models that we can use to gain insight from user data. For this instance, suppose we are looking to gauge opinions on a recent product, a film, a game, a trailer, etc.. Users might express their views via some form of text data (e.g. Tweets, reviews, Facebook posts, reddit comments). A deployed sentiment analysis model would be used to take in that data and infer the polarity of the data (positive or negative) and return to us, the number of positive and negative reviews respectively. This would be helpful to inform future product-related or marketing decisions regarding whatever product we’re putting out there.
My foci for this project were a) developing my understanding of successful model deployment on AWS Sagemaker and b) practicing writing a neural network model in pytorch and the appropriate data preprocessing functions for it. Given that this is a widely-used, canonical dataset, model performance was less of a priority. To that end I’m including below a flow-chart of the architecture (Figure 1) - to follow the logic of what happens to a user’s inputted review, start from the top left (“User’s review”) and follow the arrows to the right. I’ve included the training phase in the same diagram as deployment but it should be noted that training - shown through the righthand part of the diagram (labelled training data fed into the Sagemaker model and then stored in S3 buckets) - happens prior to deployment.
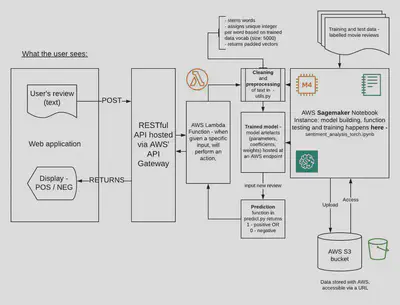
Fig 1 - Flow-chart showing how a Sagemaker notebook instance containing a Pytorch model interacts with an API, Lambda function and webapp
Model performance and issues are supervised through AWS’ CloudWatch platform, which provides a chronological log of activity from the model endpoint.
A basic webapp, API and Lambda function were written for this project as well but are non-functioning as having these hosted on Sagemaker incurs significant costs. If you’re interested in replicating the project, the code here was tested while the S3 buckets and notebooks were still fully functioning so everything should run if cloned to a Sagemaker notebook instance perfectly, asuming all files are copied over. If you’re curious to see what the final, user-facing product would look like, there are some examples in Figures 2 and 3:
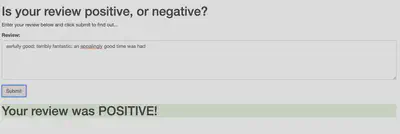
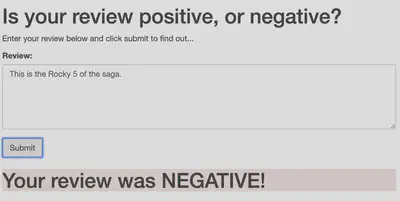
Navigation:
- SageMaker Project.ipynb - main sagemaker notebook; contains more detailed and thorrough notes and comments on how the model is built and how the various components of AWS interact with each other
- website - directory containing webapp html code
- serve - directory with necessary deployment .py files:
- model.py - model training functions
- predict.py - model deployment and inference functions
- utils.py - preprocessing functions for text data
- train - directory with additional model training files:
- requirements.txt - files needed by AWS for model to run
- dict_data - directory containing word_dict.pkl - dictionary of unique integer to word key-value pairs
A significant amount of the material for this project was learned through Udacity’s Machine Learning Engineer Nanodegree. I am grateful for their content and resources and recommend the course.
References: Data - Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. (2011). Learning Word Vectors for Sentiment Analysis. The 49th Annual Meeting of the Association for Computational Linguistics (ACL 2011). Pytorch - https://pytorch.org/ If you’re interested in learning how to use Pytorch, they provide a variety of great tutorials at https://pytorch.org/tutorials/ Udacity - https://www.udacity.com/course/machine-learning-engineer-nanodegree--nd009t