1 | Basics of Self-Attention
TL;DR — Transformers are an exciting and (relatively) new part of Machine Learning (ML) but there are a lot of concepts that need to be broken down before you can understand them. This is the first post in a column I’m writing about them. Here we focus on how the basic self-attention mechanism works, which is the first layer of a Transformer model. Essentially for each input vector Self-Attention produces a vector that is the weighted sum over the vectors in its neighbourhood. The weights are determined by the relationship or connectedness between the words. This column is aimed at ML novices and enthusiasts who are curious about what goes on under the hood of Transformers.
Contents:
1. Introduction
Transformers are an ML architecture that have been used successfully in a wide variety of NLP tasks, especially sequence to sequence (seq2seq) ones such as machine translation and text generation. In seq2seq tasks, the goal is to take a set of inputs (e.g. words in English) and produce a desirable set of outputs (- the same words in German). Since their inception in 2017, they’ve usurped the dominant architecture of their day (LSTMs) for seq2seq and have become almost ubiquitous in any news about NLP breakthroughs (for instance OpenAI’s GPT-2 even appeared in mainstream media!).

This column is intended as a very gentle, gradual introduction to the math, code and concept behind Transformer architecture. There’s no better place to start with than the attention mechanism because:
The most basic transformers rely purely on attention mechanisms³.
2. Self-Attention — the math
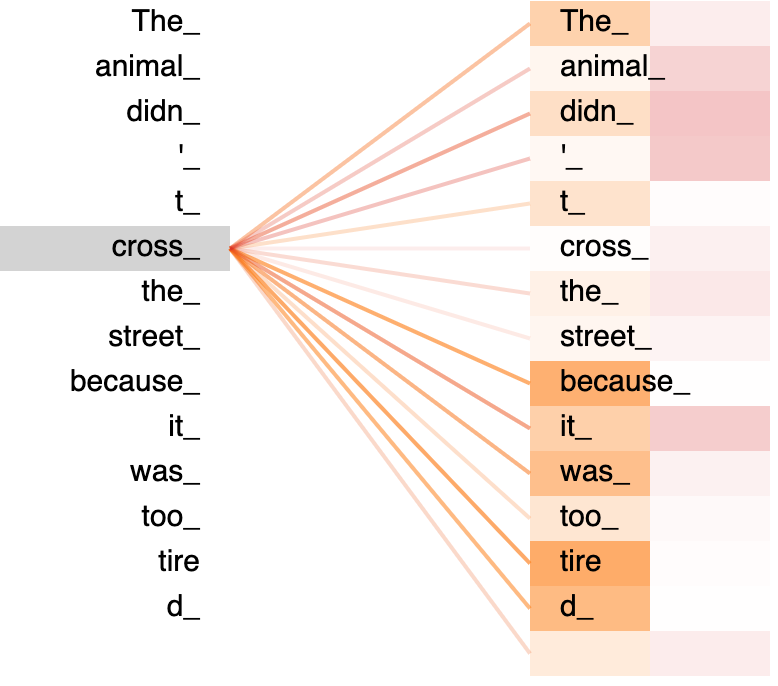
We want an ML system to learn the important relationships between words, similar to the way a human being understands words in a sentence. In Fig 2.1 you and I both know that “The” is referring to “animal” and thus should have a strong connection with that word. As the diagram’s colour coding shows, this system knows that there is some connection between “animal”, “cross”,“street” and “the” because they’re all related to “animal”, the subject of the sentence. This is achieved through Self-Attention.⁴

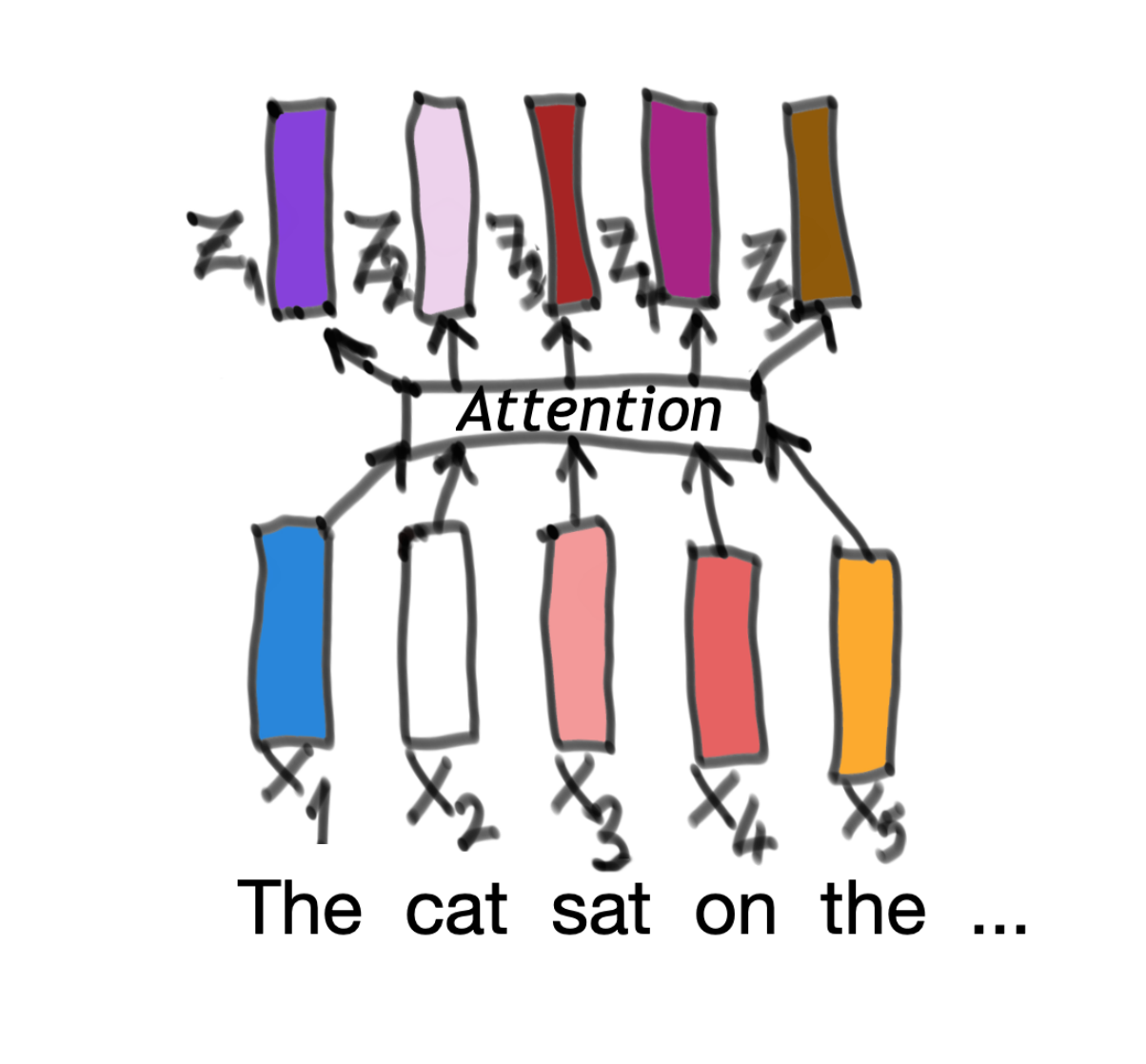
At its most basic level, Self-Attention is a process by which one sequence of vectors x is encoded into another sequence of vectors z (Fig 2.2). Each of the original vectors is just a block of numbers that represents a word. Its corresponding z vector represents both the original word and its relationship with the other words around it.
Vectors represent some sort of thing in a space, like the flow of water particles in an ocean or the effect of gravity at any point around the Earth. You can think of words as vectors in the total space of words. The direction of each word-vector means something. Similarities and differences between the vectors correspond to similarities and differences between the words themselves (I’ve written about the subject before here).
Let’s just start by looking at the first three vectors and only looking in particular at how the vector x2, our vector for “cat”, gets turned into z2. All of these steps will be repeated for each of the input vectors.
First, we multiply the vector in our spotlight, x2, with all the vectors in a sequence, including itself. We’re going to do a product of each vector and the transpose (the diagonally flipped version) of x2 (Fig 2.3). This is the same as doing a dot product and you can think of a dot product of two vectors as a measure of how similar they are.

The dot product of two vectors is proportional to the cosine of the angle between them (Fig 2.4) — so the more closely they align in direction, the larger the dot product. If they were pointing in the exact same direction then the angle A would be 0⁰ and a cosine of 0⁰ is equal to 1. If they were pointing in opposite directions (so that A = 180⁰) then the cosine would be -1.

As an aside, note that the operation we use to get this product between vectors is a hyperparameter we can choose. The dot product is just the simplest option we have and the one that’s used in Attention Is All You Need³ (AIAYN).
If you want an additional intuitive perspective on this, Bloem’s¹ post discusses how self-attention is analogous to the way recommender systems determine the similarity of movies or users.
So we put one word under the spotlight at a time and determine its output from its neighbourhood of words. Here we’re only looking at the words before and after but we could choose to widen that window in the future.

If the spotlit word is “cat”, the sequence of words we’re going over is “the”, “cat”, “sat”. We’re asking how much attention the word “cat” should pay to “the”, “cat” and “sat” respectively (similar to what we see in Fig 2.1).
Multiplying the transpose of our spotlit word vector and the sequence of words around it will give us a set of 3 raw weights (Fig 2.5). Each weight is proportional to how connected the two words are in meaning. We need to then normalise them so they are easier to use going ahead. We’ll do this using the softmax formula (Fig 2.6). This converts a sequence of numbers to be within the range of 0, 1 where each output is proportional to the exponential of the input number. This makes our weights much easier to use and interpret.
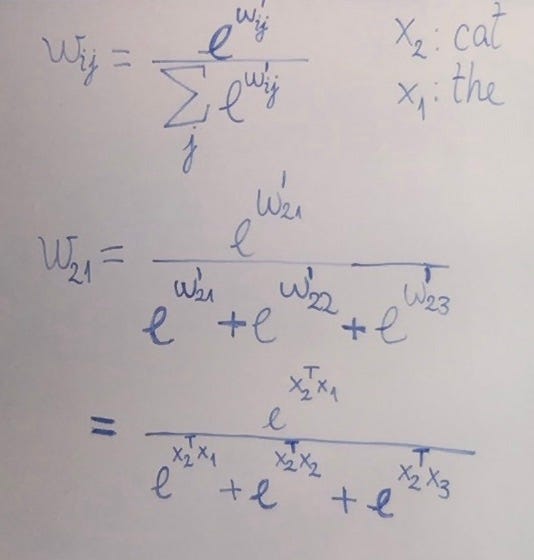
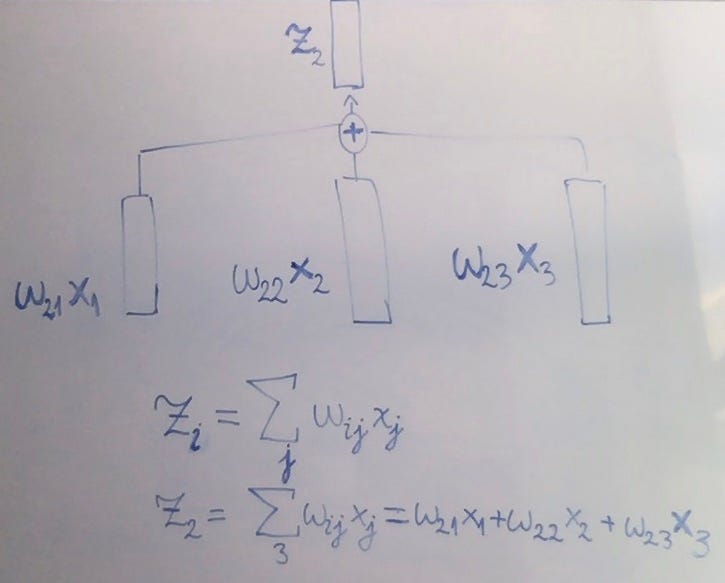
Now we take our normalised weights (one per every vector in the j sequence), multiply them respectively with the x input vectors, sum the products and bingo! We have an output z vector, (Fig 2.5)! This is, of course, the output vector just for x2 (“cat”) — this operation will be repeated for every input vector in x until we get the output sequence we saw in Fig 2.2.
This explanation so far may have raised some questions:
- Aren’t the weights we calculated highly dependent on how we determined the original input vectors?
- Why are we relying on the similarity of the vectors? What if we want to find a connection between two ‘dissimilar’ words, such as the object and subject of “The cat sat on the matt”?
In the next post, we’ll address these questions. We’ll transform each vector for each of its different uses and thus define relationships between words more precisely so that we can get an output more like Fig 2.8.
I hope you’ve enjoyed this post and I appreciate any amount of claps. Feel free to leave any feedback (positive or constructive) in the comments and I’ll aim to take it onboard as quickly as I can.
The people who helped my understanding the most and to whom I am very grateful are Peter Bloem (his post is a great start if, like me, you prefer a math-first approach to Machine Learning¹ ) and Jay Alammar (if you want a top-down view to start with, I recommend his article²).
3. References
- Alammar J. The Illustrated Transformer. (2018) https://jalammar.github.io/illustrated-transformer/ [accessed 27th June 2020]
- Bloem P. Transformers from Scratch. (2019) http://www.peterbloem.nl/blog/transformers .[accessed 27th June 2020]
- Vaswani A. et al. Dec 2017. Attention is all you need. 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA. https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf [accessed 27th June 2020]. arXiv:1706.03762
- Vaswani A. et al. Mar 2018 arXiv:1803.07416 . Interactive notebook: [accessed 29th June 2020]